利用扣子平台搭建获取抖音某用户主页的视频文案并写入多维表格的工作流
1. 准备工作
(1) 获取用户视频插件说明文档(参考上期文章):
https://www.nutpi.net/thread?topicId=2774
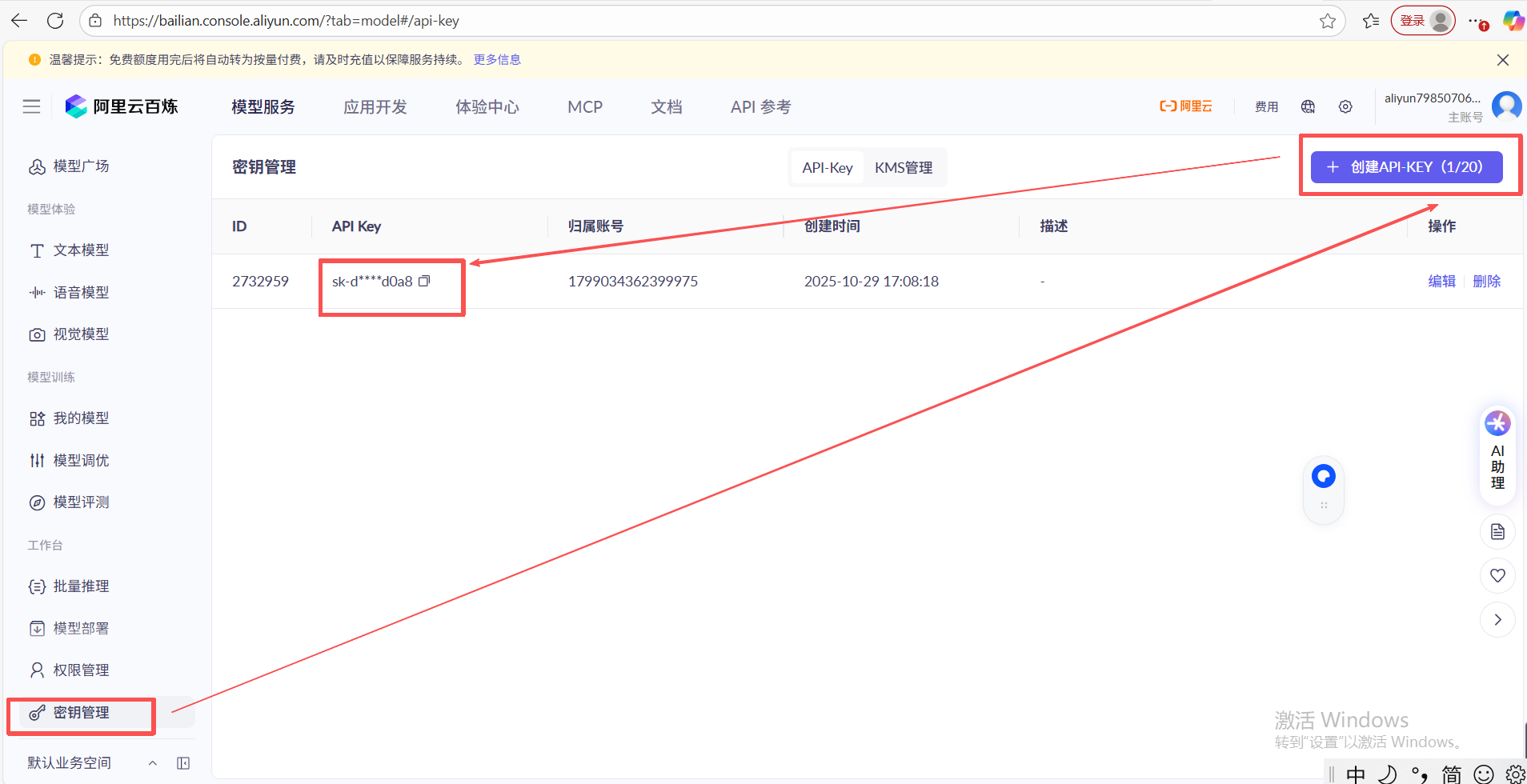
(2) 注册阿里云百炼:https://bailian.console.aliyun.com/?tab=model#/api-key
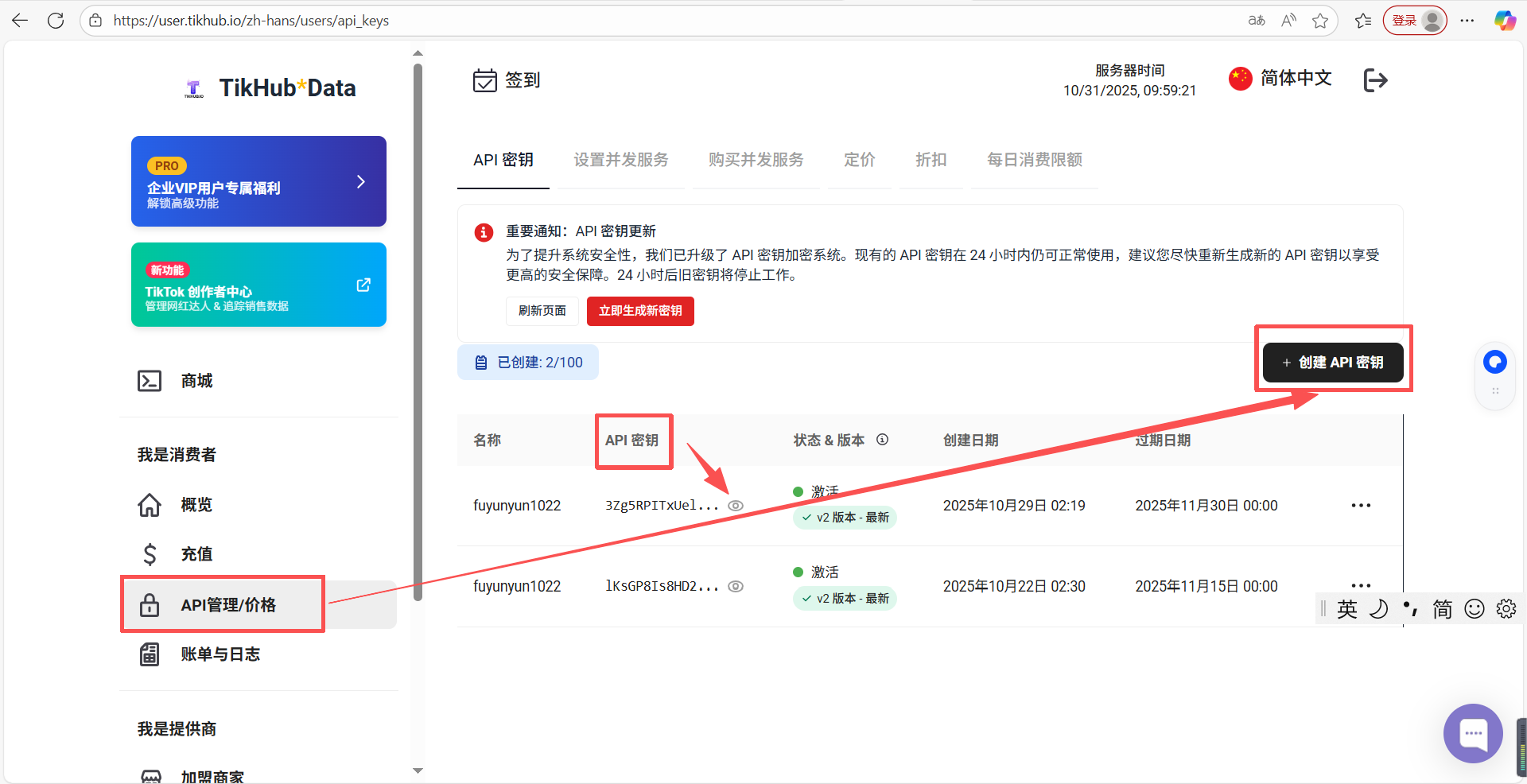
(3) Tikhub:https://user.tikhub.io/zh-hans/users/overview
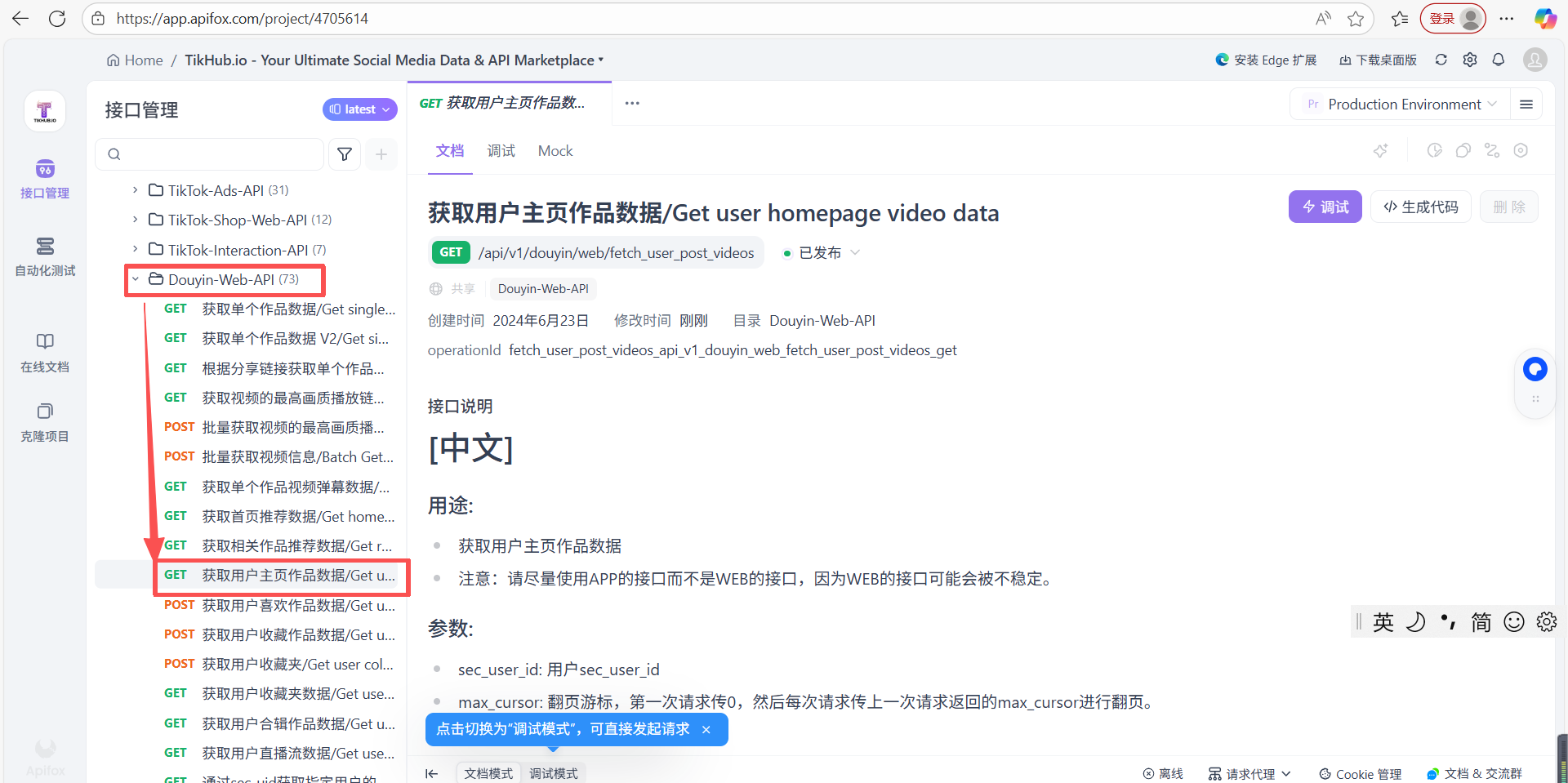
(4) 参考文档:https://app.apifox.com/project/4705614
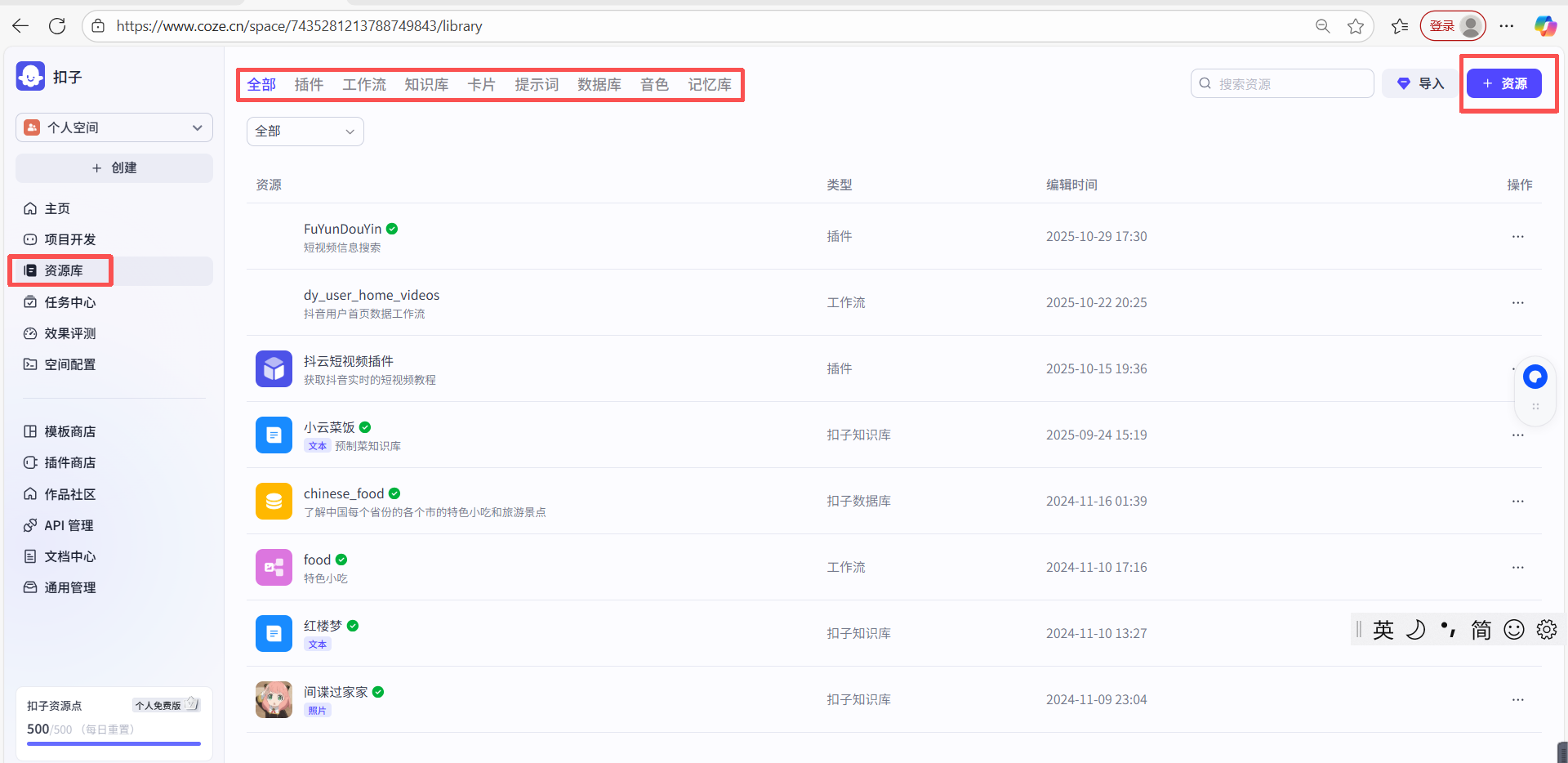
(5) 扣子开发平台:https://www.coze.cn/home
2. 搭建获取抖音用户视频文案的工作流
(1) 设置开始的参数
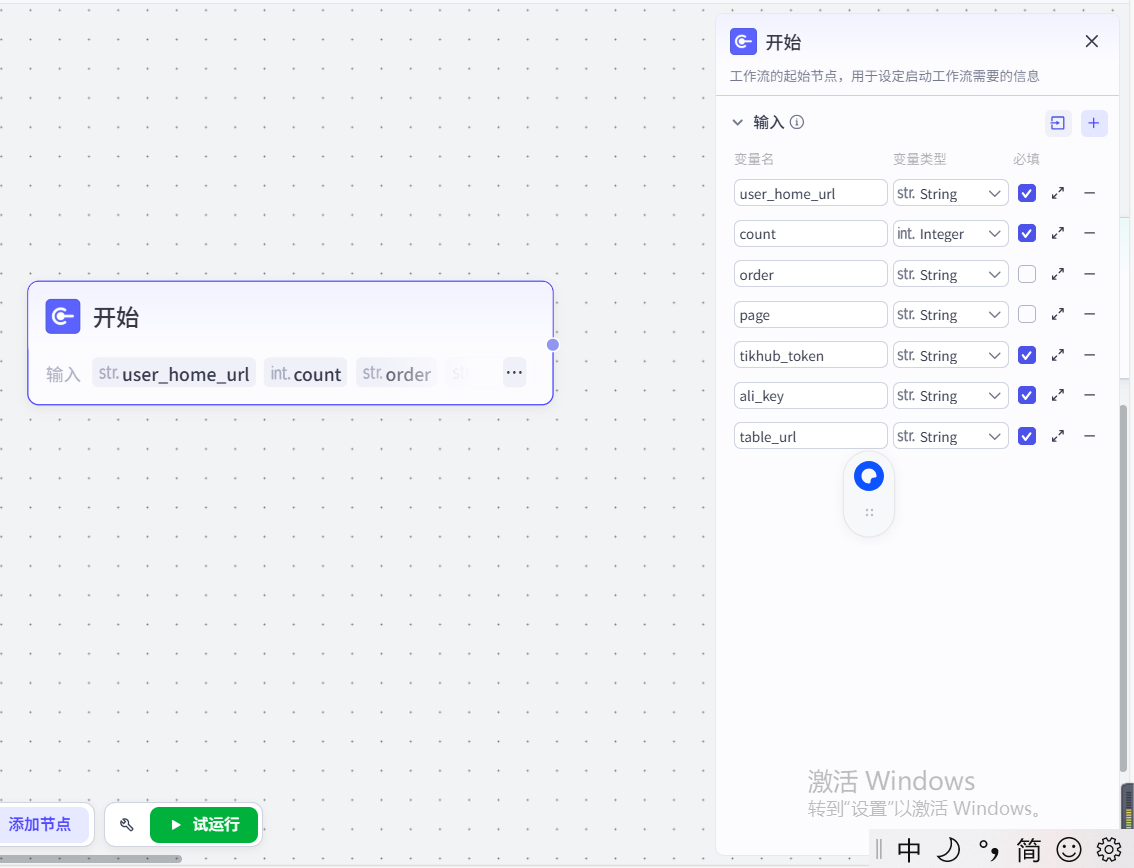
(2) 加入代码节点
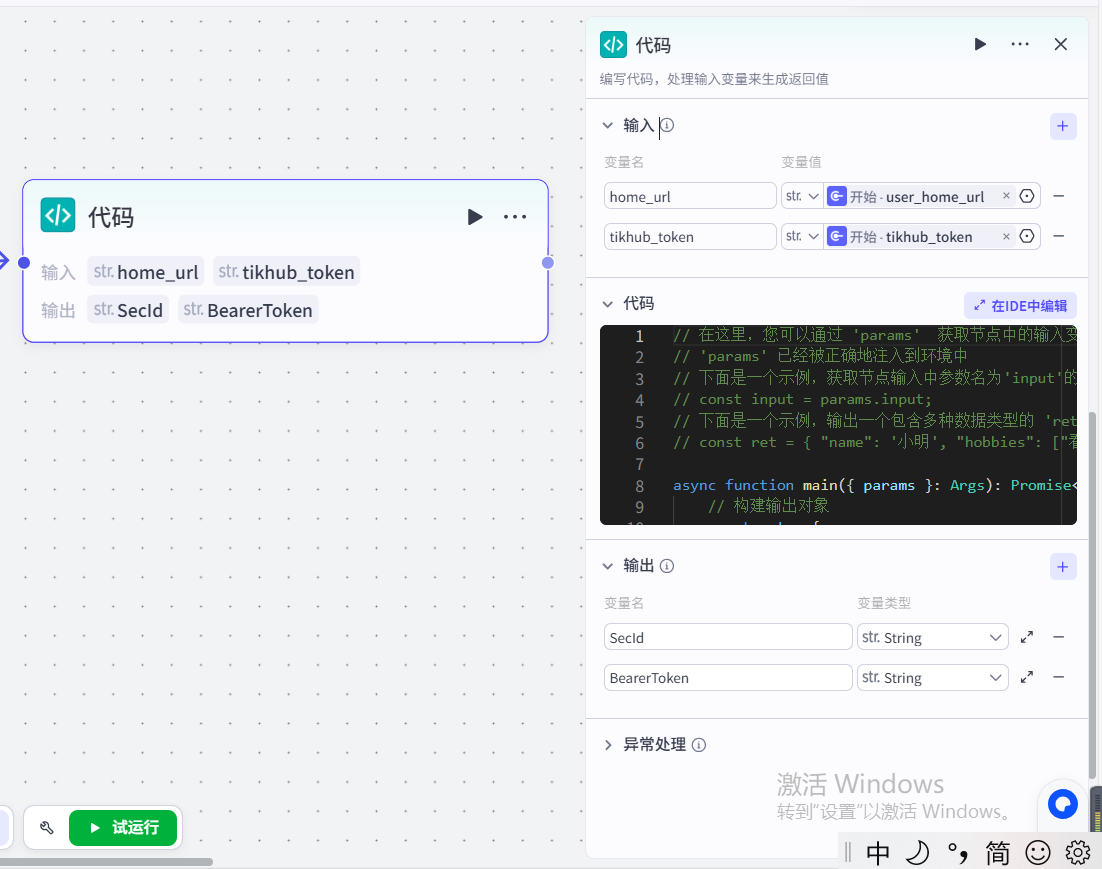
该js代码功能是将输入的用户抖音主页的链接进行提取第二段路径,代码如下所示:
async function main({ params }: Args): Promise<Output> {
// 构建输出对象
const ret = {
"SecId": getSecondPathSegment(params.home_url), // 返回网址中的第二段路径
"BearerToken": "Bearer " + params.tikhub_token, // 返回一个加前缀Bearer的token
};
return ret;
}
function getSecondPathSegment(url) {
/**
* 提取URL中的第二段路径(路径按'/'分割,忽略空值和参数)
*
* @param {string} url - 输入的完整URL
* @returns {string|null} 第二段路径(若不存在则返回null)
*/
try {
// 1. 解析URL(浏览器和Node.js 10+均支持URL对象)
const parsedUrl = new URL(url);
const path = parsedUrl.pathname; // 获取路径,自动排除参数和锚点
// 2. 按'/'分割路径,过滤空字符串
const pathSegments = path.split('/').filter(seg => seg.trim() !== '');
// 3. 返回第二段路径,不存在则返回null
return pathSegments.length >= 2 ? pathSegments[1] : null;
} catch (error) {
// 若URL格式错误,捕获异常并返回null
console.error("URL格式无效:", error);
return null;
}
}
// ------------------- 测试 -------------------
const targetUrl = "https://www.douyin.com/user/MS4wLjABAAAATxjw25jXAmBJGh82wGxFmSN2F1S3IPEJ8t5UJX5qc9YXqwr8QsgD28XZ5XTRcZJ1?from_tab_name=main&vid=7563257988643818778";
const result = getSecondPathSegment(targetUrl);
console.log("第二段路径:", result);
// 输出:第二段路径: MS4wLjABAAAATxjw25jXAmBJGh82wGxFmSN2F1S3IPEJ8t5UJX5qc9YXqwr8QsgD28XZ5XTRcZJ1
测试该代码节点,输出正确的用户secId即可进行下一步操作,如下图所示: 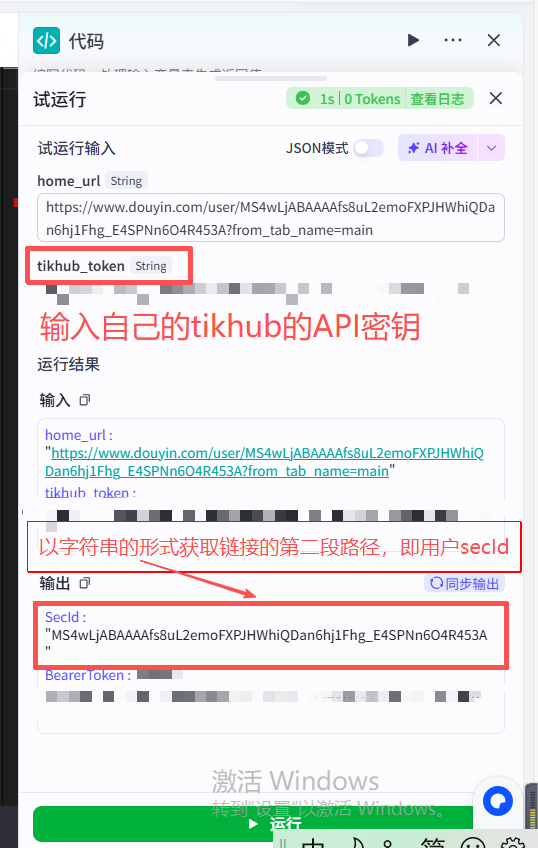
(3) 选取自己资源库中所创建的插件
获取用户视频插件说明文档:https://www.nutpi.net/thread?topicId=2774 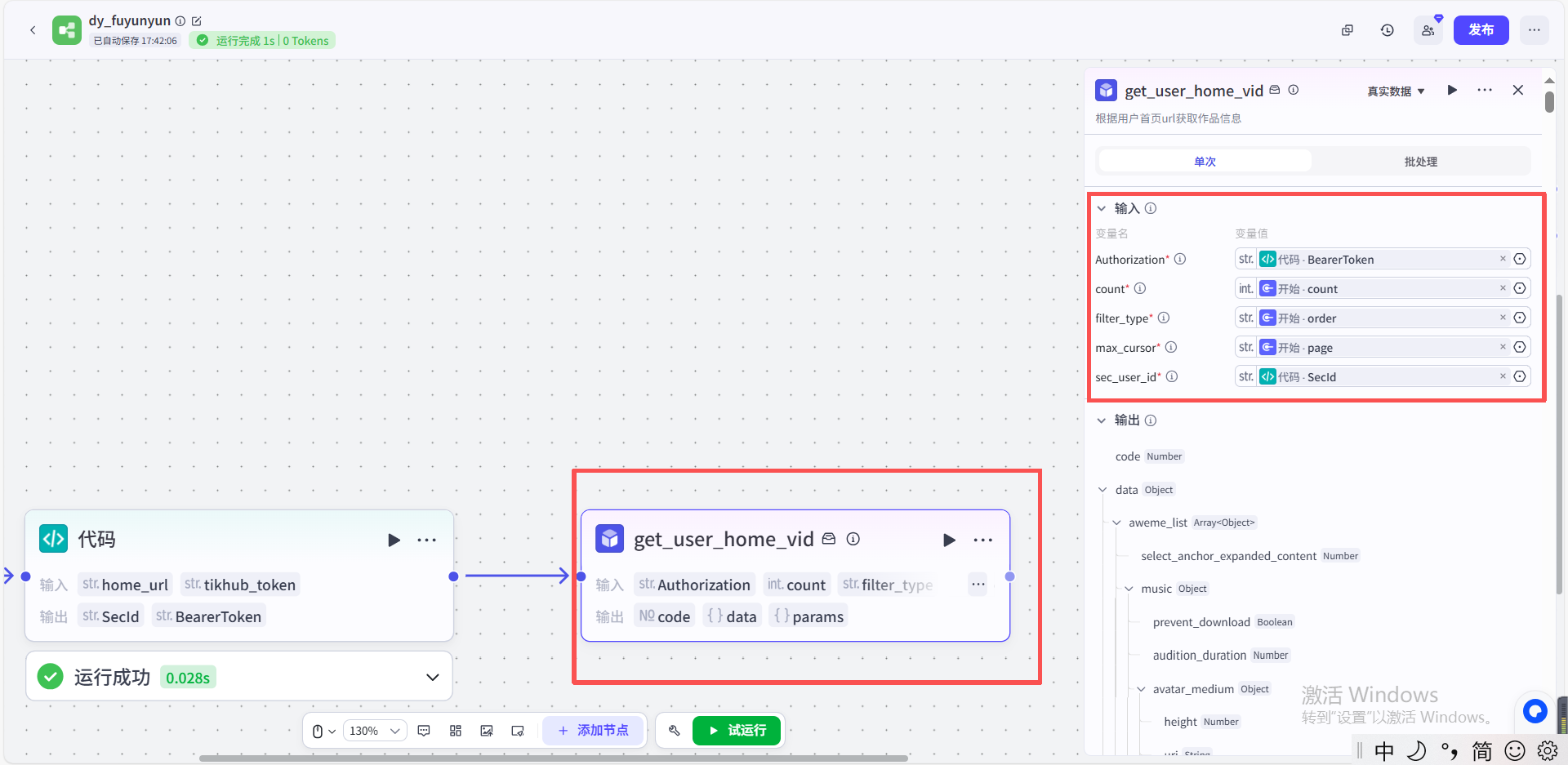
(4) 设置获取的条件
使用选择器获取该用户的视频列表,且视频数量必须是大于0的 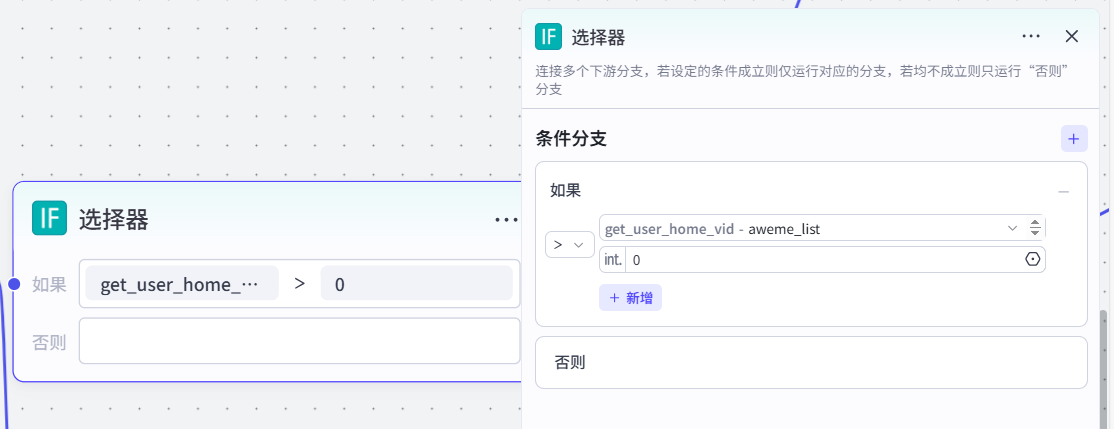
(5) 加入批处理节点
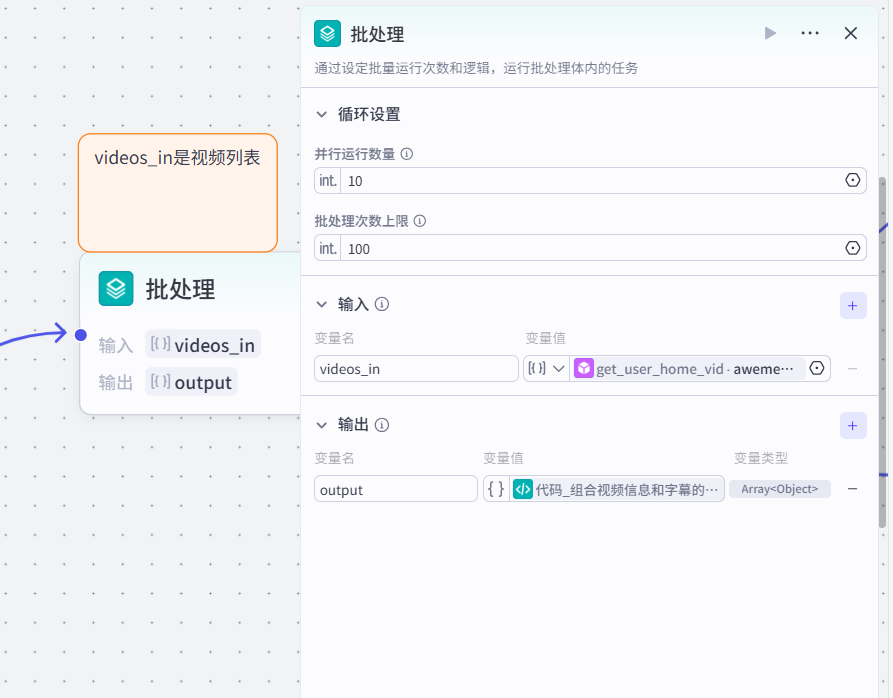
(6) 在批处理里面加入“获取字幕”的插件
选取通步处理的字幕获取的插件,如下图所示: 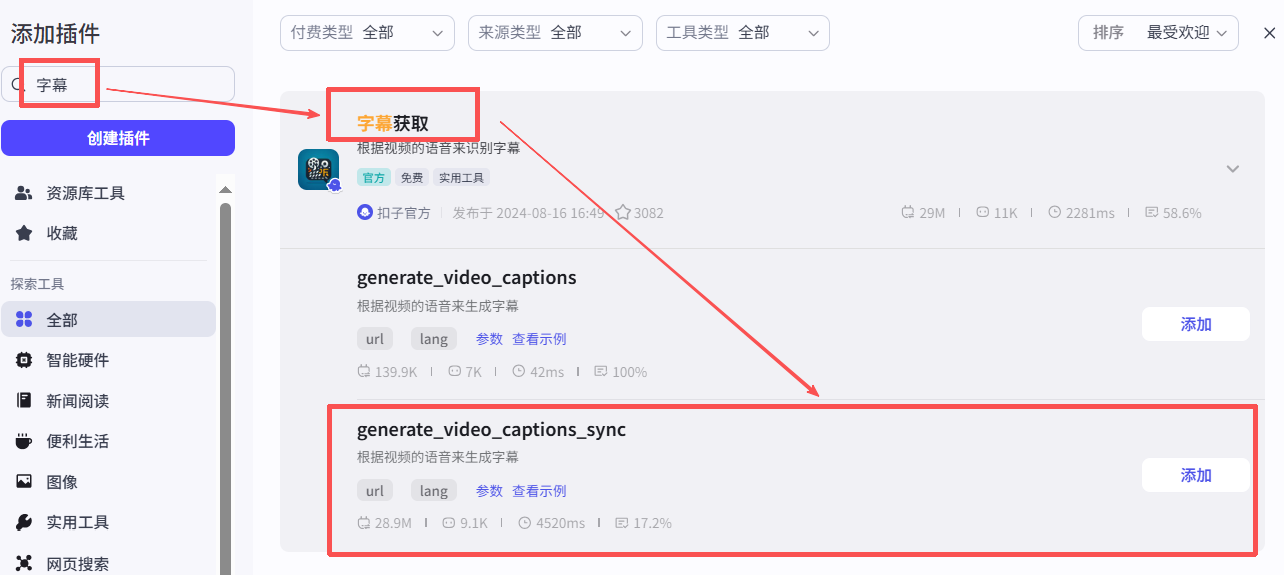
设置“字幕获取”插件的输入参数,来生成文案的字幕,输入参数配置如下图所示: 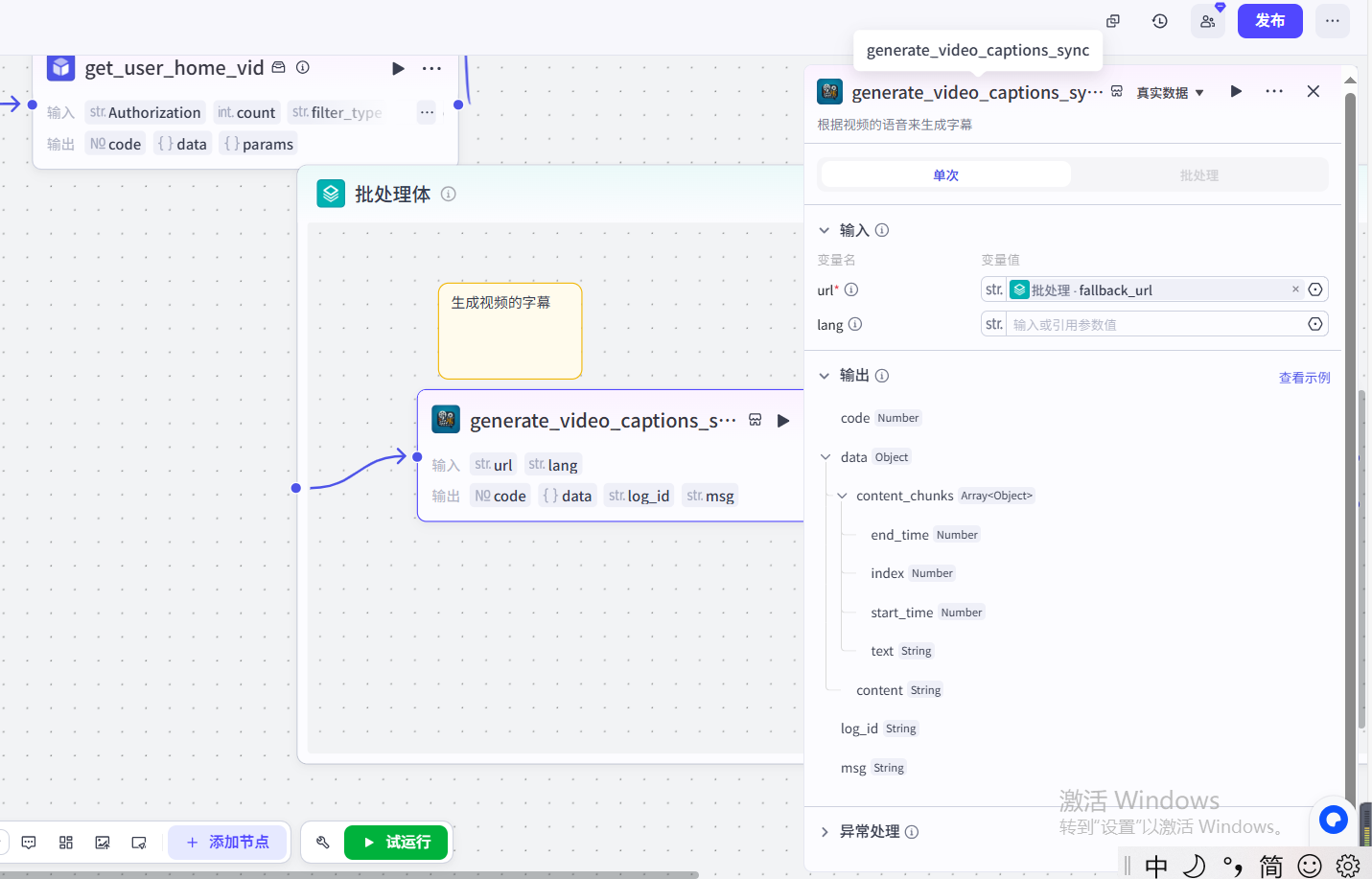
(7) 条件选择器(双重校验)
判断“视频字幕生成的同步数据是否为空” 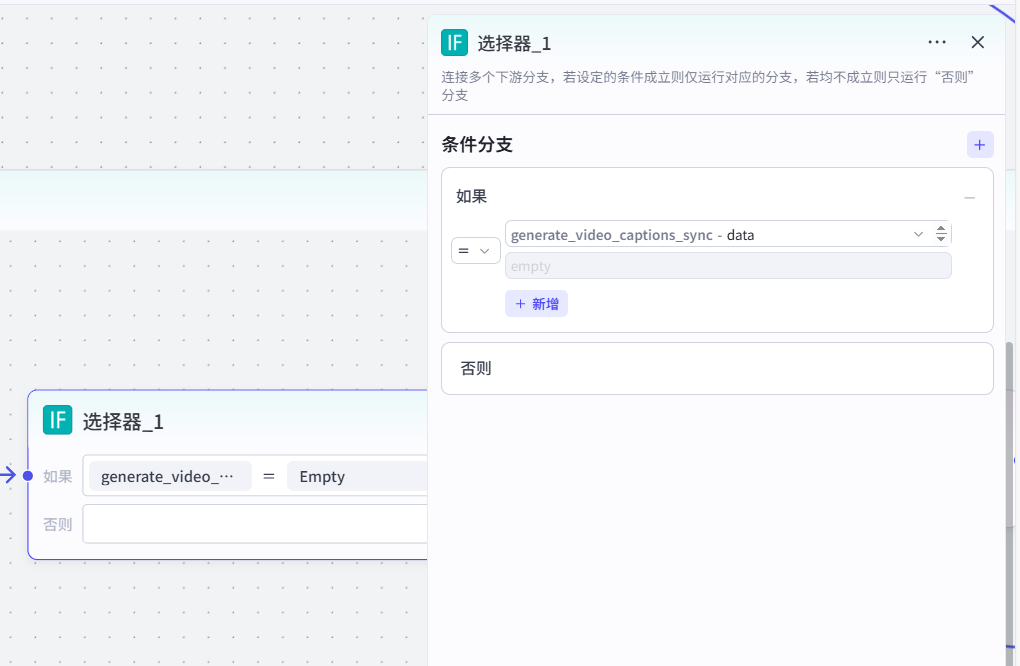
若视频字幕生成的同步数据为空时,则插入阿里云百炼的语音识别插件接口(当没有现成的视频字幕时,通过语音识别从音频中提取文字): 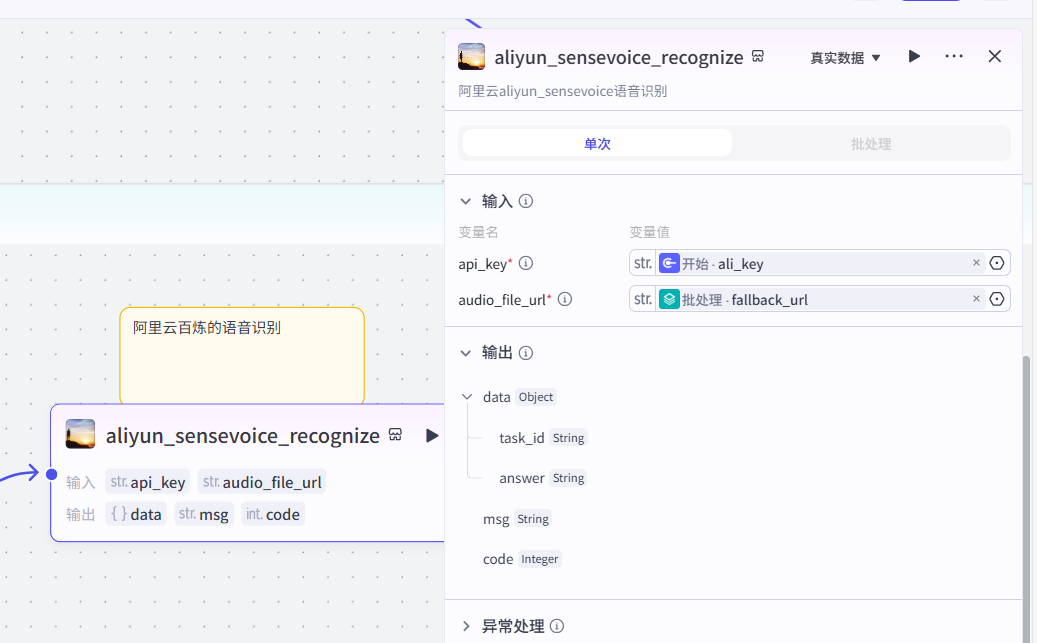 并接入变量聚合,同下(视频字幕生成的同步数据不为空). 若视频字幕生成的同步数据不为空时,则已获取到视频的字幕数据,即进行变量聚合操作: 该变量聚合共有两个来源: 来源1:generate_video_captions_sync-content(原视频字幕内容) 来源2:aliyun_sensevoice_recognize-answer(语音识别出的文字结果)
并接入变量聚合,同下(视频字幕生成的同步数据不为空). 若视频字幕生成的同步数据不为空时,则已获取到视频的字幕数据,即进行变量聚合操作: 该变量聚合共有两个来源: 来源1:generate_video_captions_sync-content(原视频字幕内容) 来源2:aliyun_sensevoice_recognize-answer(语音识别出的文字结果) 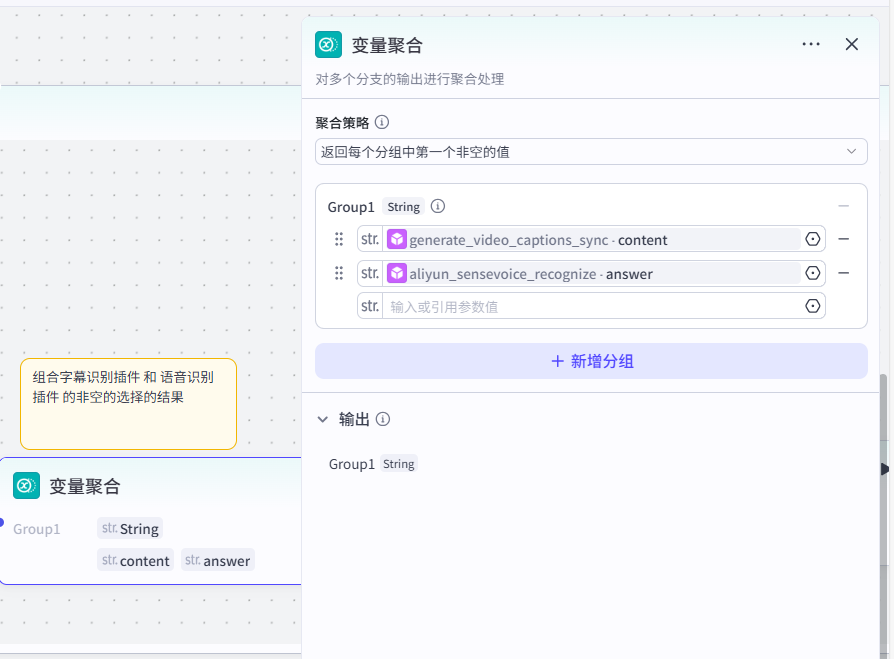 根据上面的操作,就可以可靠地获取到视频的文案字幕信息啦!
根据上面的操作,就可以可靠地获取到视频的文案字幕信息啦!
(8) 将获取到的视频文案的字幕信息接入到代码
该代码是和飞书的多维表格的属性标题一定要对应哦,可以中文也可以英文,对应好就ok了。 注意:飞书一定要授权扣子的使用哦,且飞书的多维表格一定要可让所有人进行编辑哦,否则就自动写不进去了!!!
多维表格权限如下图所示 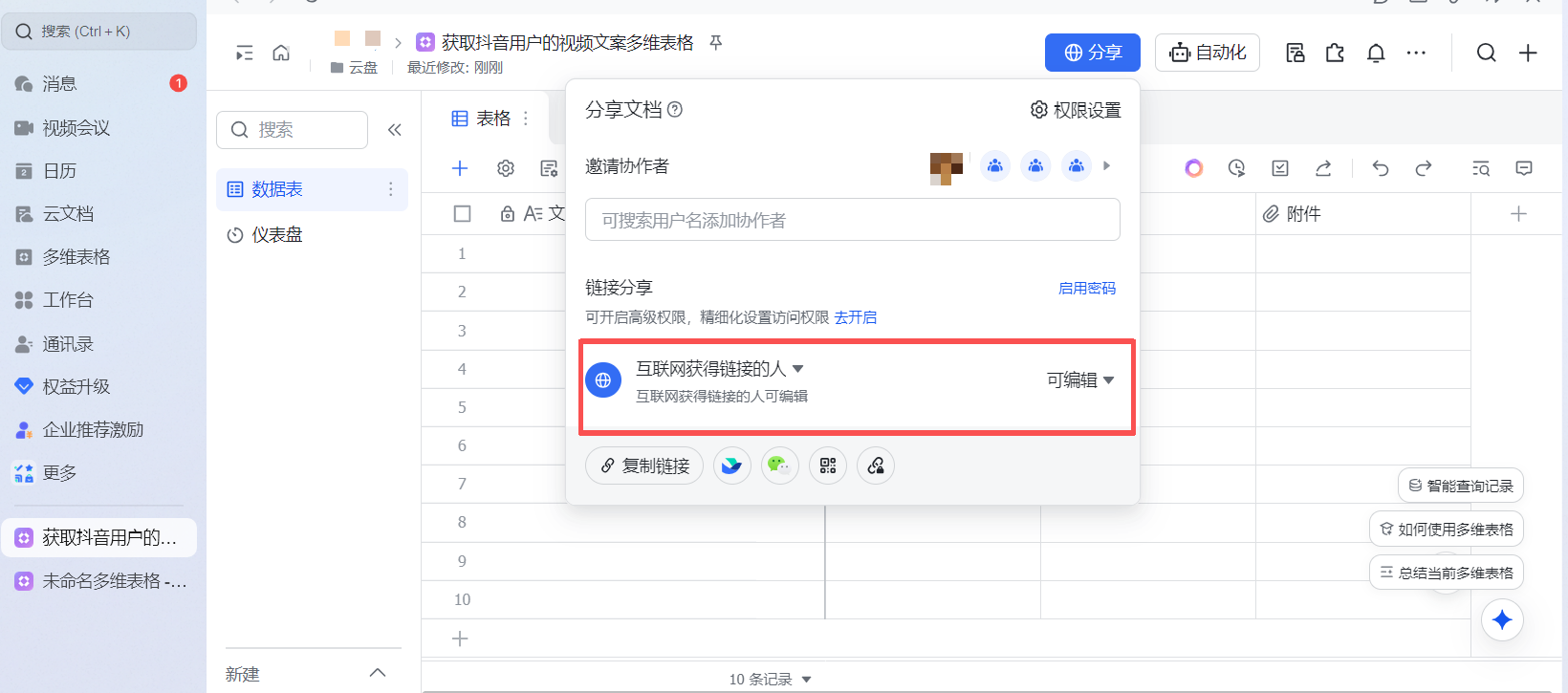
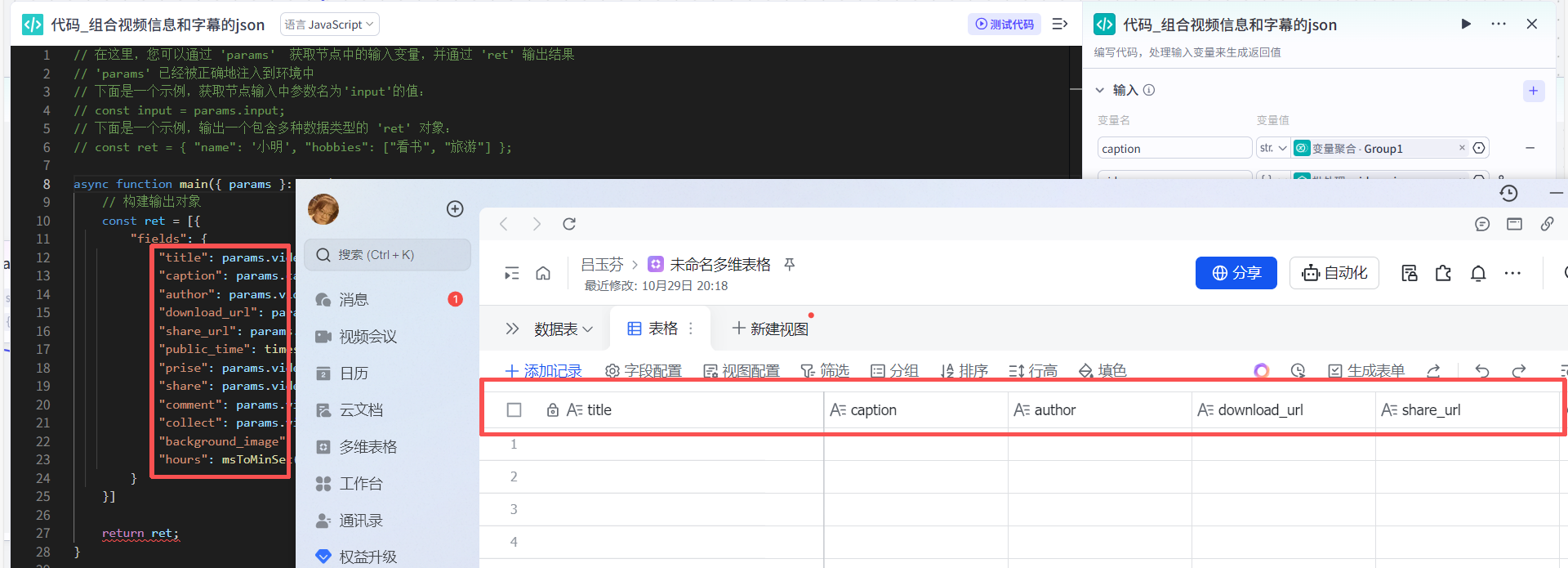
将获取到的数据进行处理,js代码如下所示:
async function main({ params }: Args): Promise<Output> {
// 构建输出对象
const ret = [{
"fields": {
"title": params.video.desc, // 标题
"caption": params.caption, // 文案
"author": params.video.author.nickname, // 作者
"download_url": params.video.video.bit_rate[0].play_addr.url_list.pop(), // 取最后一个视频的地址
"share_url": params.video.share_info.share_url, // 分享链接
"public_time": timestampToYMDHText(params.video.create_time), // 发布时间(时间戳)
"prise": params.video.statistics.digg_count, // 点赞数
"share": params.video.statistics.share_count, // 分享数
"comment": params.video.statistics.comment_count, // 评论数
"collect": params.video.statistics.collect_count, // 收藏数
"background_image": params.video.video.cover.url_list[0], // 封面图
"hours": msToMinSec(params.video.duration) // 时长(转换为分秒格式)
}
}]
return ret;
}
/**
* 将时间戳转换为"某年某月某日某时"文本格式
* @param {number} timestamp - 时间戳(毫秒级,如1730169600000)
* @returns {string} 格式化后的字符串(如:2024年10月30日14时)
*/
function timestampToYMDHText(timestamp) {
// 处理秒级时间戳(自动转为毫秒级)
if (timestamp < 1e12) {
timestamp *= 1000;
}
const date = new Date(timestamp);
// 获取年月日时(月份从0开始,需+1)
const year = date.getFullYear();
const month = date.getMonth() + 1; // 无需补0,直接使用数字(如10月)
const day = date.getDate();
const hour = date.getHours();
// 拼接为"某年某月某日某时"格式
return `${year}年${month}月${day}日${hour}时`;
}
/**
* 将毫秒时长转换为分秒格式(mm:ss)
* @param {number} milliseconds - 毫秒时长(如125000毫秒 = 2分5秒)
* @returns {string} 格式化后的分秒字符串(如:02:05)
*/
function msToMinSec(milliseconds) {
// 处理非数字或负数情况
if (typeof milliseconds !== 'number' || milliseconds < 0) {
return '00:00';
}
// 1. 转换为总秒数(向下取整,忽略毫秒部分)
const totalSeconds = Math.floor(milliseconds / 1000);
// 2. 计算分钟和剩余秒数
const minutes = Math.floor(totalSeconds / 60);
const seconds = totalSeconds % 60;
// 3. 补全为两位数,拼接为 mm:ss 格式
return `${String(minutes).padStart(2, '0')}:${String(seconds).padStart(2, '0')}`;
}
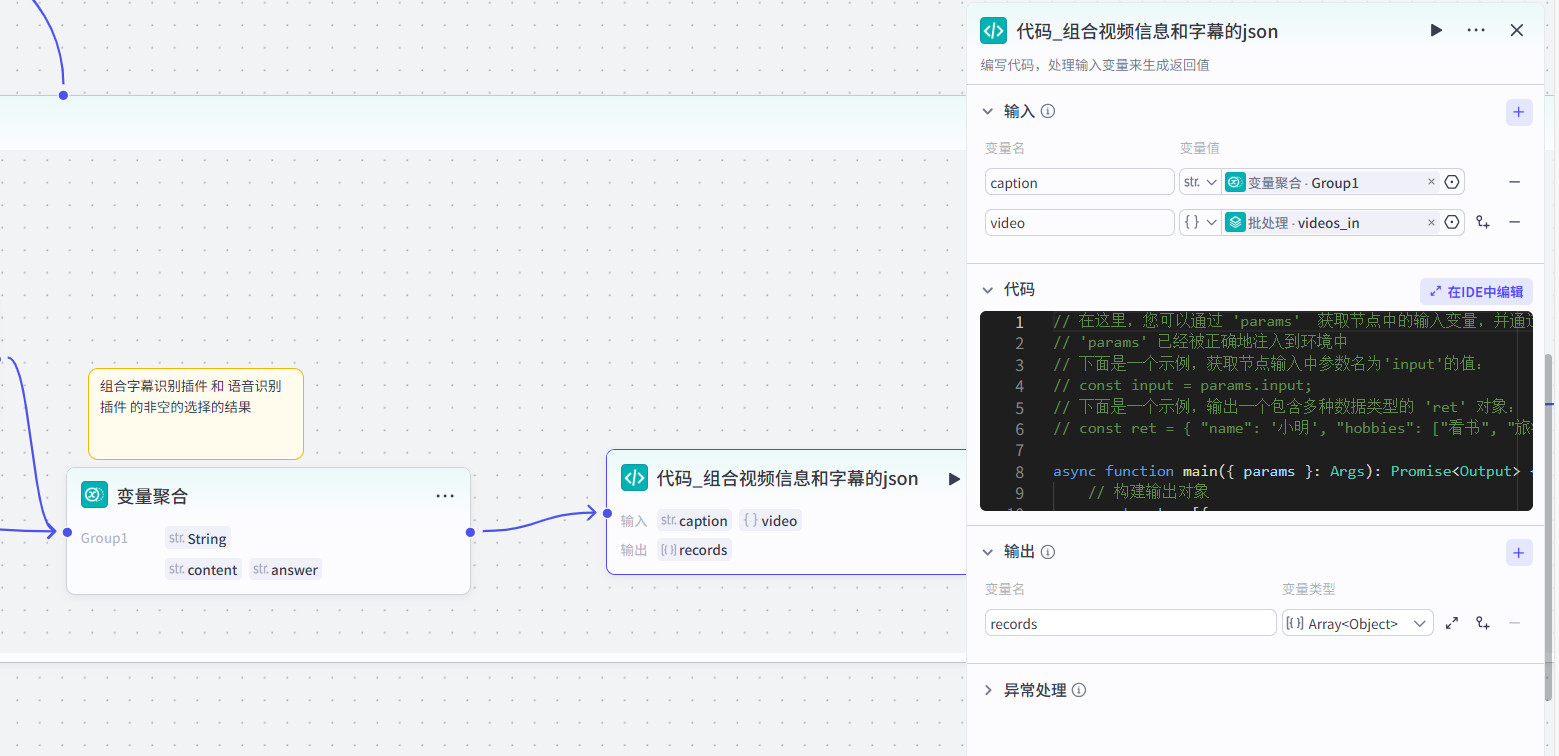
(9) 添加“飞书多为表格”插件
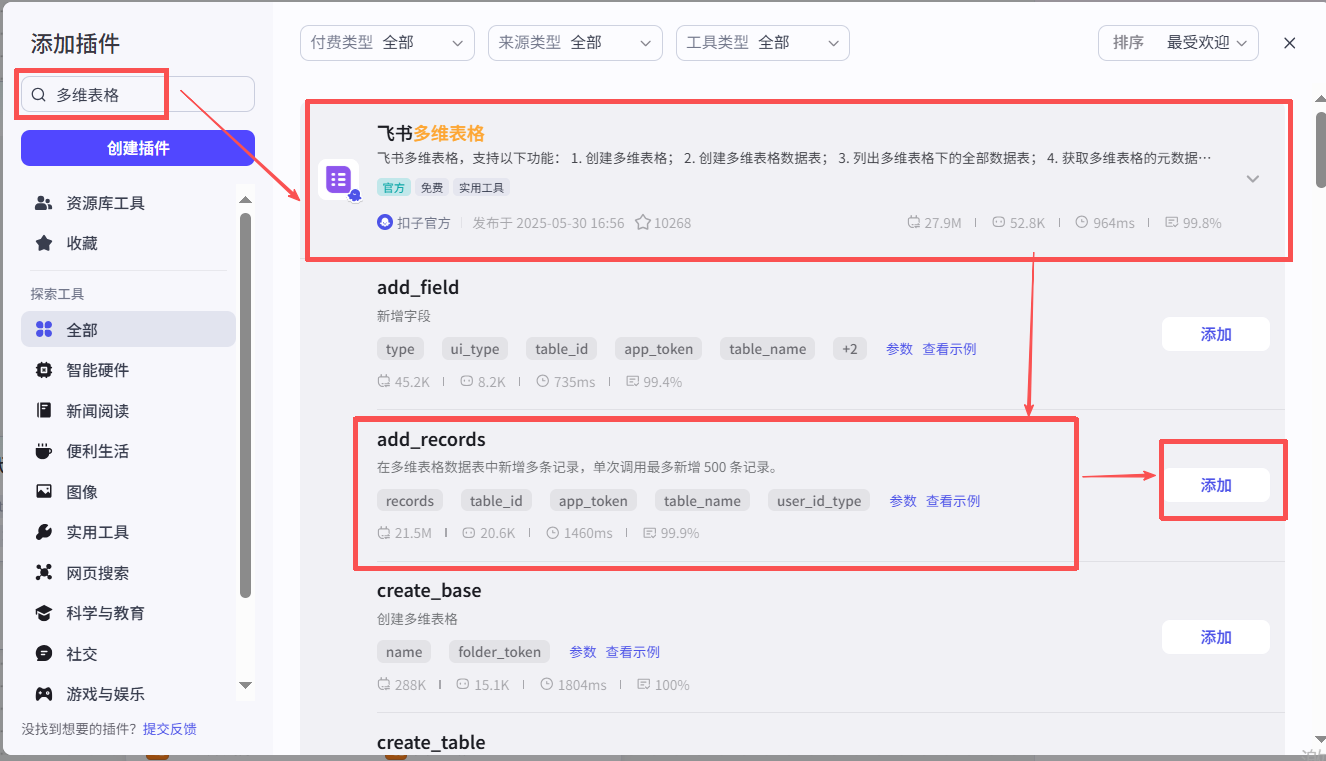
设置参数: 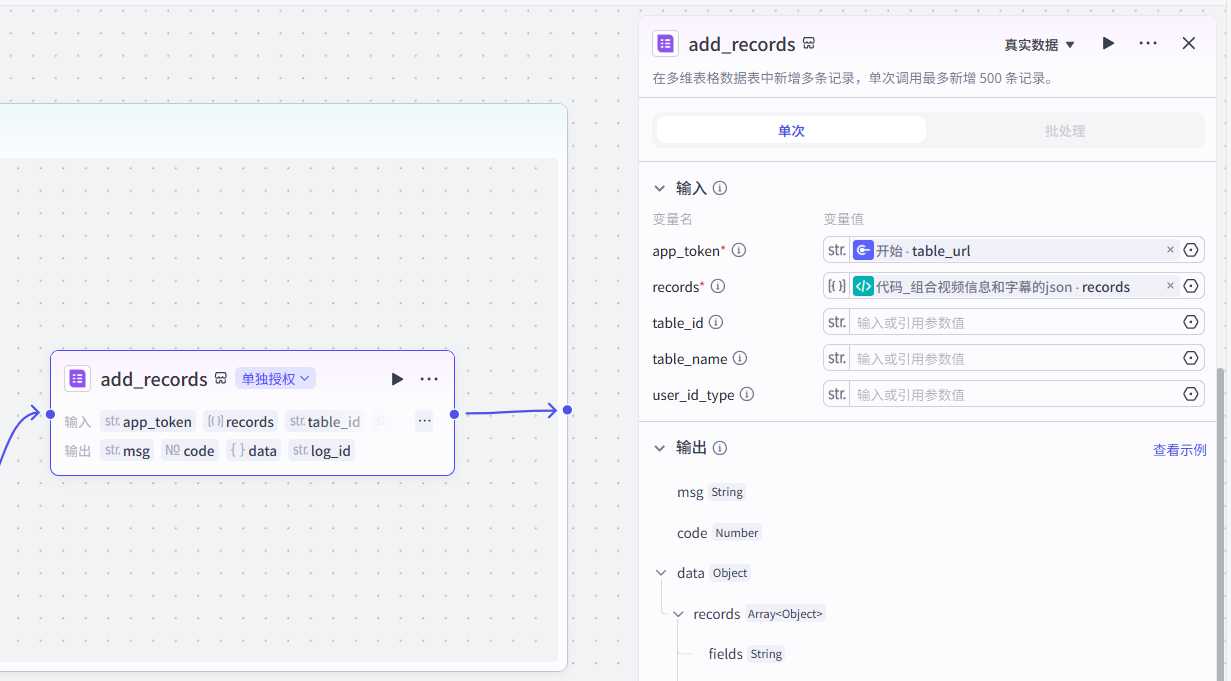
(10) 连接结束的节点并配置输入输出的参数
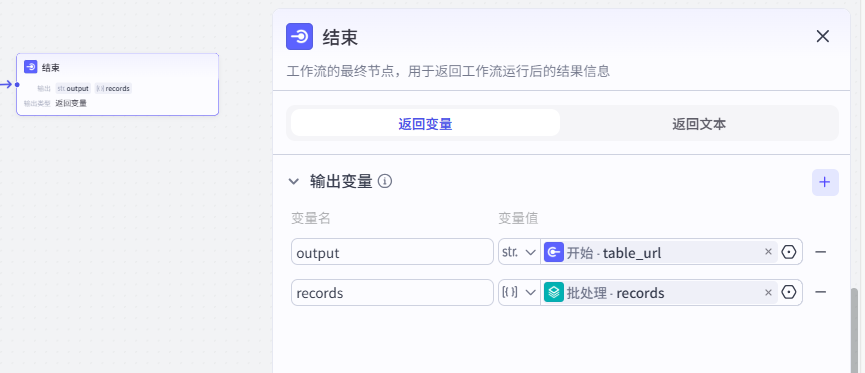
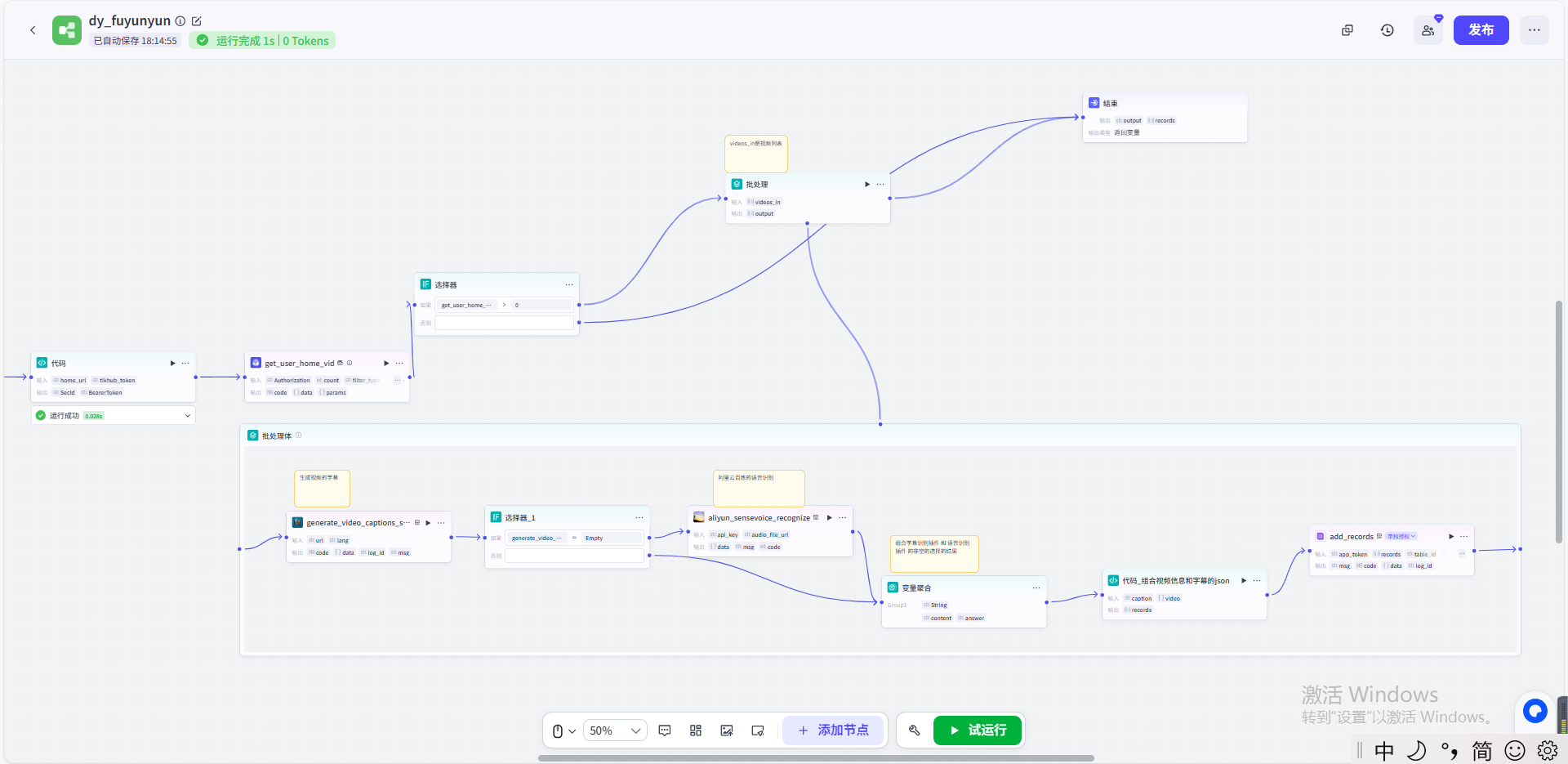 根据上述操作,则利用扣子平台搭建获取用户视频列表的文案的工作流就搭建好啦!
根据上述操作,则利用扣子平台搭建获取用户视频列表的文案的工作流就搭建好啦!
3. 试运行
以该用户,读取3个作品的文案写入多维表格为例: https://www.douyin.com/user/MS4wLjABAAAA9wtaKPoAxyJ-4U8hDK-5K7yZMMLdWYjwoxIg2rC5DPxQr3KuXOQ1IN_aYvXjAMBq?from_tab_name=main&vid=7555074594747829513 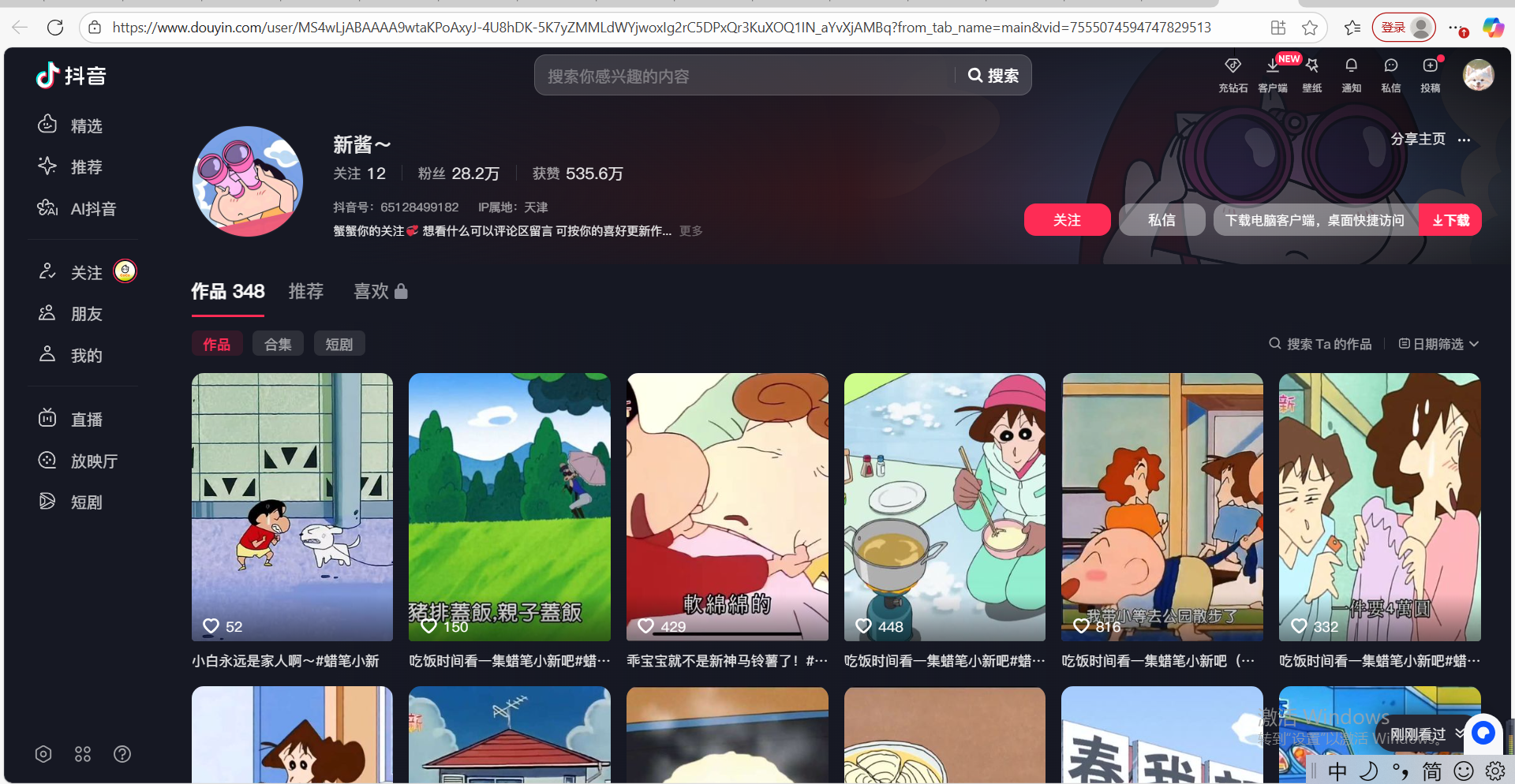
写入输入参数,查看运行结果: 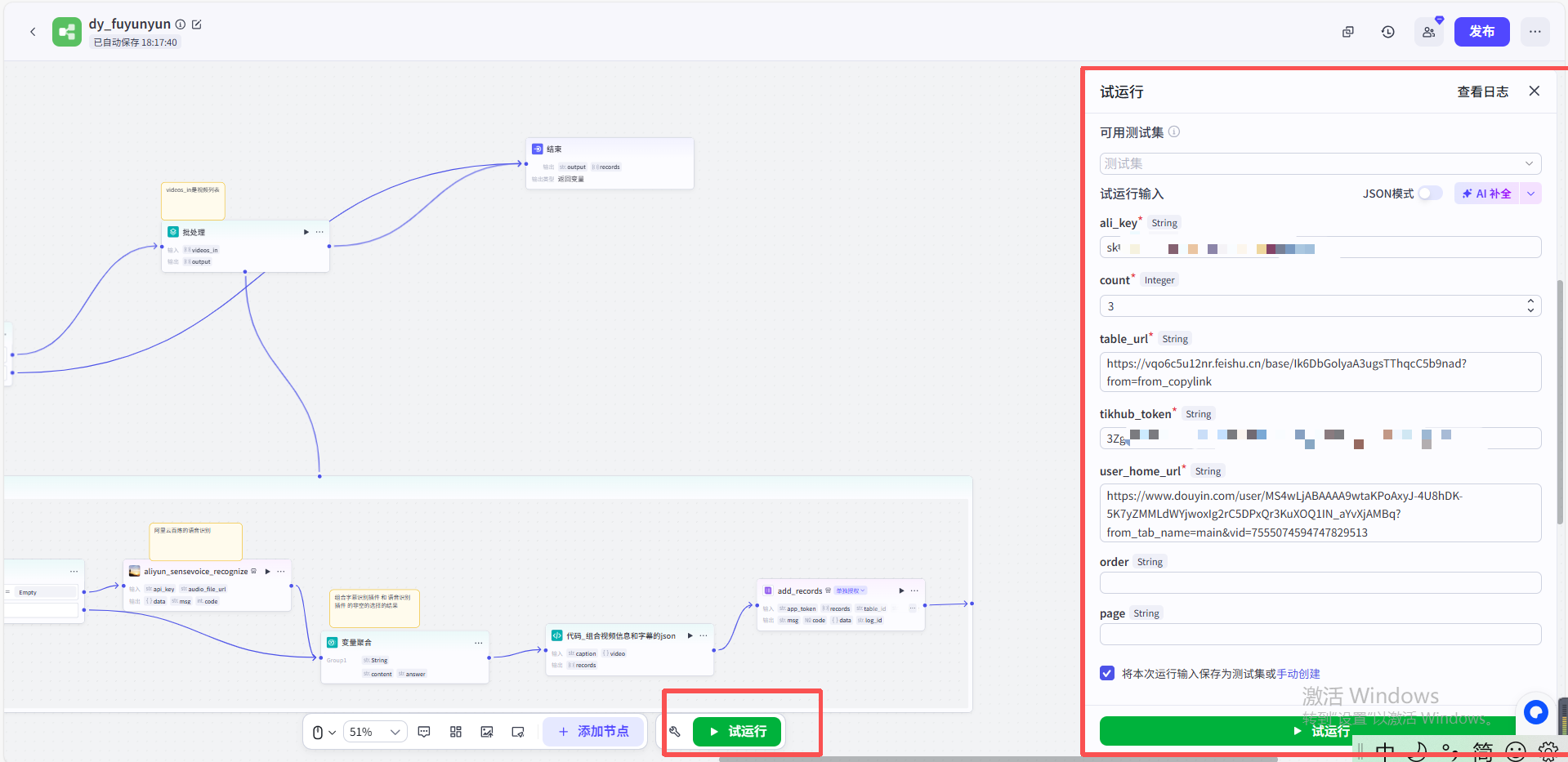
工作流一定要全部运行成功哦,如下图所示: 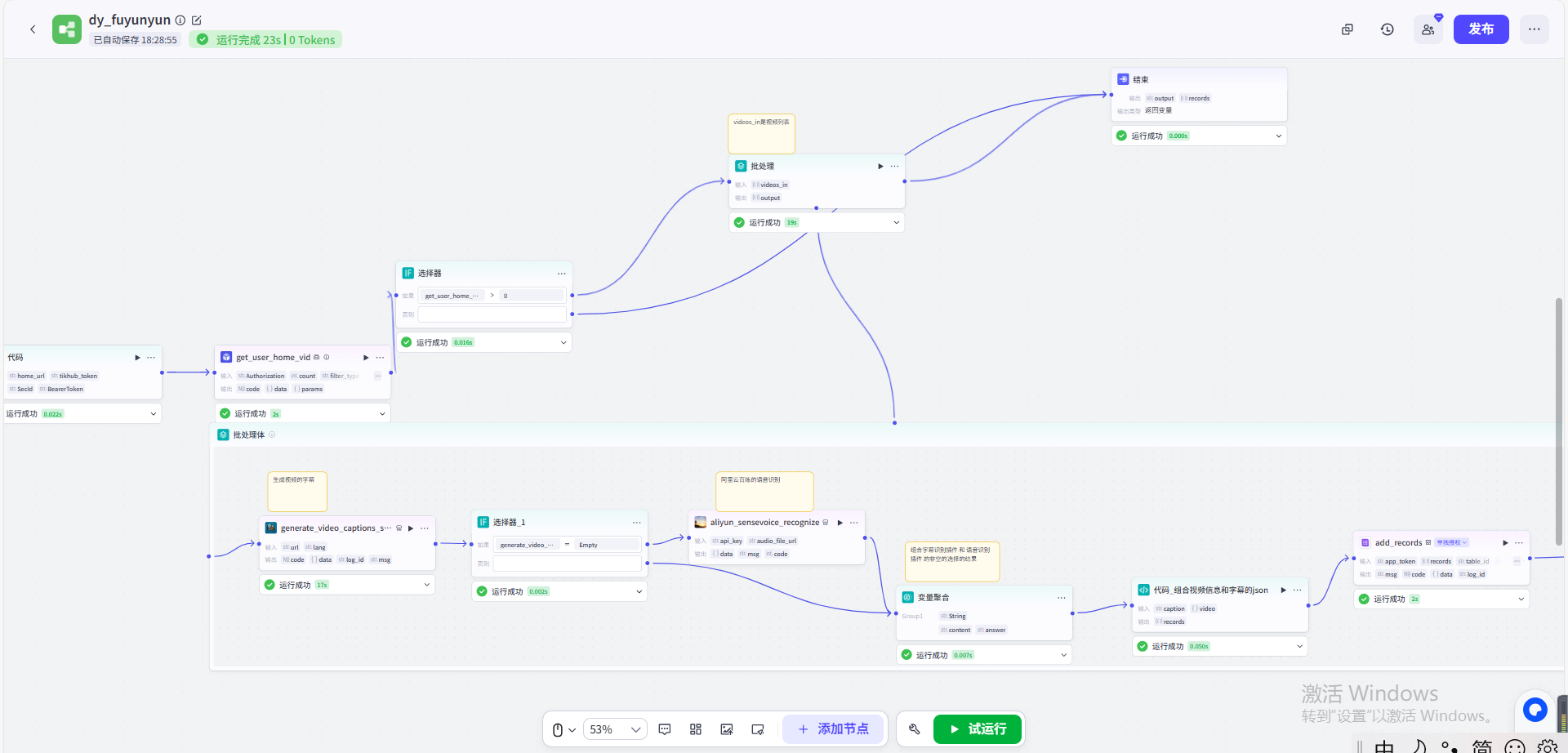
最终,飞书的多维表格就已经被该工作流写入 {{ count }} 数量个的字幕文案,即3条数据,如下图所示:
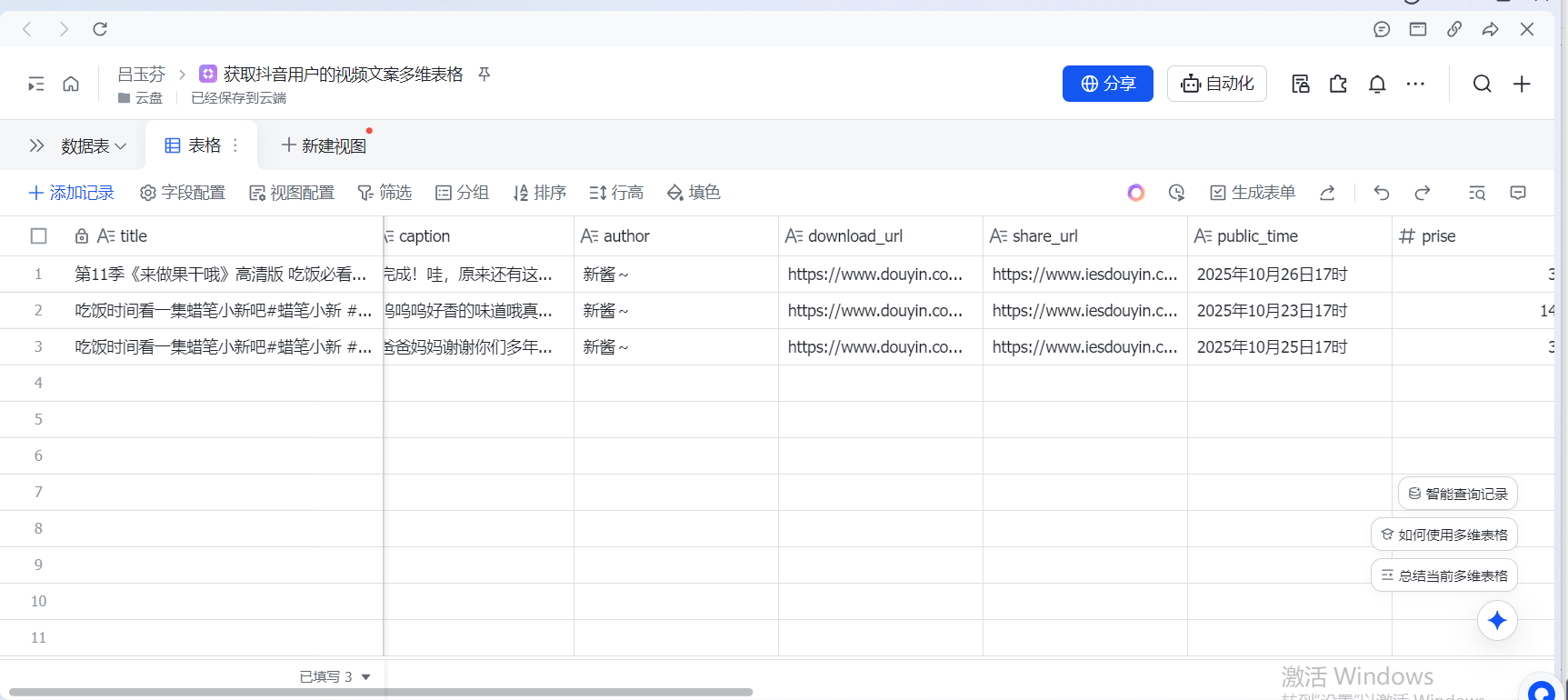
如上所示,即允许成功,按照个人自愿来进行发布/不发布。
总结
通过扣子平台搭建“获取抖音用户视频列表文案”的工作流,明确get_user_home_vid-aweme_list等每个参数的作用。通过配置条件选择器判断数据状态,结合变量聚合整合视频文案信息,过程中不断调试接口参数、优化分支逻辑,解决了数据空值和流程阻塞等问题。这次实践不仅让我掌握了低代码工具搭建复杂工作流的方法,还提升了对第三方平台数据交互与流程自动化的理解,为后续类似场景的工作流开发积累了实用经验。
联系方式
| 有问题可以根据以下方式联系我哟~ | |
|---|---|
| 联系方式 | 账号名/账号 |
| 3277508694@qq.com | |
| VX | LYFER041227 |
| Github | fyy534 |
欢迎各位有问题来咨询哦😀!!!
